PEAKS Online Overview
Use PEAKS Online to take advantage of powerful, shared computing resources to perform LC-MS/MS protein and peptide identification and quantification analyses. With the ability to run on any all-in-one installation, multi-CPU cluster, or cloud server, the restructured software platform allows large datasets to be processed efficiently by multiple users at the same time.
PEAKS Online, means high-throughput proteomics data analysis for multiple users on a network. Although the term ‘Online’ is often associated with the world wide web, PEAKS Online should not be confused with public access. Instead, PEAKS Online is a software package which includes a Server licence and Client licences and can be hosted on a public cloud such as AWS or Google Cloud or it can be deployed on a private network such as your own high-performance computing cluster. This cloud-based architecture allows PEAKS Online to be fully parallelised and scalable to your lab’s needs and is ideal for processing large-scale projects.
PEAKS Online provides users with the ability to utilise the established PEAKS workflows more efficiently and on a larger scale. The interactive tool used to send/retrieve data to/from the server is called PEAKS Client, and the results are presented in a similar manner as available in the PEAKS Studio desktop solution. Through the Web Client Interface or Client Command Line Interface (CLI), multiple users can also access the PEAKS Online server at the same time, supporting parallelism at the project and data level.
Computer Specifications
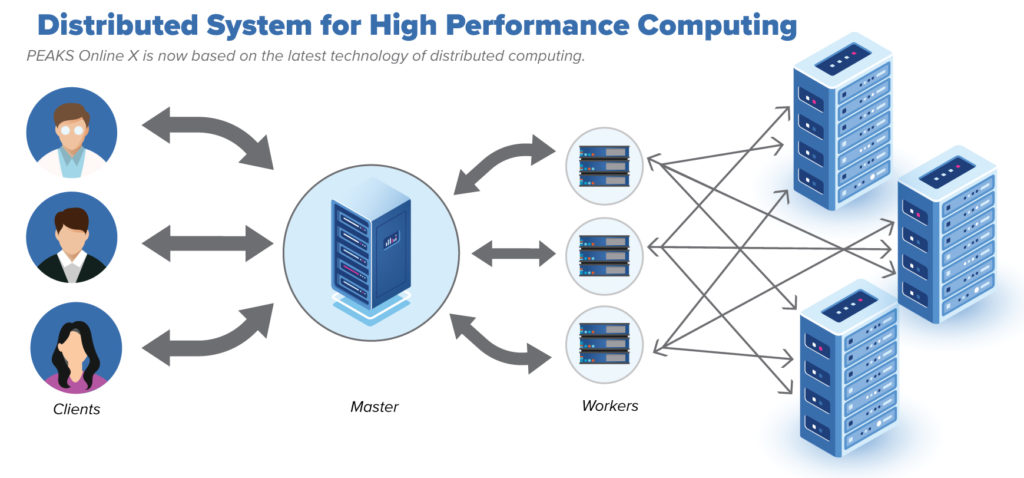
Overall, PEAKS Online is composed of 3 components: the Database Node(s), Master Node, and Worker Node(s). These can be distributed to different computers, or placed on the same machine. Each component has a unique pattern of computing resource usage and hardware requirements.
Database Node(s) of PEAKS Online store all application data and are the base for all proteomics processing. Since PEAKS Online is a distributed computing framework that can run from multiple machines, we use the popular distributed database system Cassandra as the main data storage to provide I/O performance at scale. Each data node, as part of a Cassandra cluster, has high demand for memory space and disk I/O speed.
The Master Node is the central hub of PEAKS Online X’s computing framework. It takes charge of scheduling, dispatching, and synchronisation of computing tasks. Although it does not perform any data processing, it takes care of the web based user interface, loading of raw data and exporting of result data, and would benefit more from high performance CPUs.
Worker Nodes are responsible for the actual data processing and computation. PEAKS Online is easily scalable, so a worker node can be configured to use a customised number of CPU threads. As a rule of thumb, a worker node needs 2GB available memory for each computing thread and another 2GB spare memory for its own usage. Other than a few GB for logging, a worker node generally has no requirement for hard disk I/O speed nor space.